Paper Summary — torch.manual_seed(3407) is all you need
Whenever we train a neural network from scratch, it’s weights are initialized with random values. So, if you re-run the same training job again and again, the values used to initialized the weights will keep on changing as they would be randomly generated.
Now just imagine, metric of a State of the Art architecture for a given task is 80. You propose a new architecture for the same task and train your model from scratch. After you run it once (assuming all hyper-parameters were just perfect), you get 79.8 metric value. For some reason, you then just re-run the experiment keeping everything unchanged. You get 80.2 metric value and your architecture has now surpassed previous SOTA’s performance. Apart from weights of the neural network being randomly initialized, every other value/hyper-parameter was left unchanged during the second trial! So what do you think the reason might be?
Let’s look at the summary of the paper — torch.manual_seed(3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision by David Picard. Link of the paper : Paper Link.
Note — If I quote anything from the paper it’ll be italic and inside quotes. For example — “this is an example”
Abstract
The author investigates the “effect of random seed selection on the accuracy” of a deep learning architecture for perception models. He has done so by scanning up to 10⁴ seeds on datasets such as CIFAR-10 and on the ImageNet dataset by using pre-trained models. “The conclusions are that even if the variance is not very large, it is surprisingly easy to find an outlier that performs much better or much worse than the average.”
Introduction
The main aim of the experiment is :-
- “What is the distribution of scores with respect to the choice of seed? ”
- “Are there black swans, i.e., seeds that produce radically different results?”
- “Does pretraining on larger datasets mitigate variability induced by the choice of seed?”
These questions are important to discuss/ask because it’s a common practice in domains relying on machine learning because the papers report only single run of the experiment performed. Like the table in the papers (papers say who claim the new SOTA and prove it with experimental result) just show Architecture-small = X metric value, Architecture-medium = Y metric value, etc. They don’t mention Architecture-small = X metric value (1st run), Architecture-small = X metric value (2nd run), etc. As per the author this trend is there because of limited computing resources and having one at least one result is better than no result at all!
Like physical experiments have noise in the measurement the same way we have random initialization, data split in train and test, etc. The author then tells that if the effect of setting random seeds for different experiments is negligible then things are fine but if not then the publications should include “detailed analysis of the contribution of each random factor to the variation in observed performances”
Experimental Setup
For CIFAR 10 — some 10,000 seeds were explored where each seed experiment took 30 seconds to train on evaluate. GPU used by the author was V100. The model used was custom ResNet with 9 layers.
For ImageNet, since it was nearly impossible train neural networks from scratch with so many seeds, the author used pretrained models “where only the classification layer is initialized from scratch.” The author used three different models — Supervised ResNet 50, SSL ResNet 50 and SSL ViT.
(Please refer the paper to know more about the training setup)
Limitations
The author informs that this experiments has many limitations which affects the final conclusion of the experiment.
The accuracy from the experiments the author ran is not at par with SOTA results because of budget constraints. CIFAR 10’s accuracy achieved is some how comparable to ResNet’s result from 2016. “This means papers from that era may have been subject to the sensitivity to the seed” that the author observes.
For ResNet50 model trained on ImageNet dataset, in DINO paper, the authors say that they get improved accuracy by tweaking the hyperparameters. But still the author believes that experiments done with ImageNet “underestimate the variability because they all start from the same pretrained model, which means the effect of the seed is limited to initialization of the classification layer and the optimization process.
The author also says that these limitations would have overcome if 10 times more computation budget was available on CIFAR dataset and 50 to 100 times more computation budget was available for ImageNet models.
Findings
Convergence instability
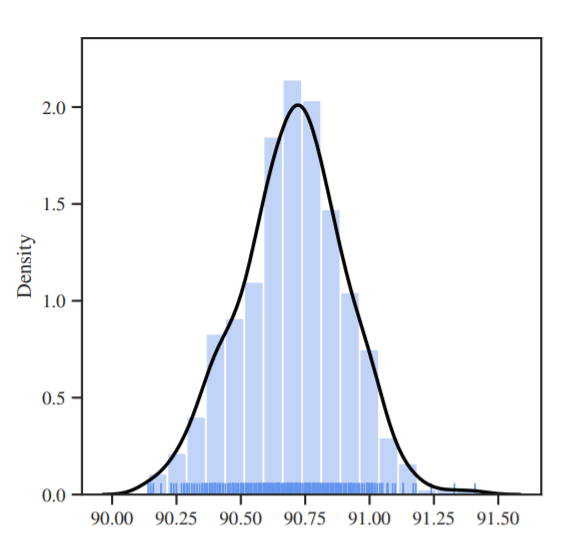
This histograms shows density plot of final validation accuracy on CIFAR10 dataset on 500 seeds. Each das line is one run.
We can see a lot of dash lines at accuracy 90.50% and 91.00%. “Hence a 0.5% difference in accuracy could be entirely explained by just a seed difference, without having chosen a particularly bad or good seed.”
“The answer to first question is thus that the distribution of scores with respect to the seeds is fairly concentrated and sort of pointy. This is a reassuring result because it means that scores are likely to be representative of what the model and the training setup can do, expect when one is actively searching (knowingly or unknowingly) for a good/bad seed.”
Searching for Black Swans
Short training setup was used to scan 10⁴ seeds. The minimum and maximum values are 89.01% and 90.83% respectively. This difference of 1.82% is termed as significant difference in the domain! This difference means whether or not the paper on the new SOTA can be published or not!
“The results of this test allow me to answer positively to the second question: there are indeed seeds that produce scores sufficiently good (respectively bad) to be considered as a significant improvement (respectively downgrade) by the computer vision community. This is a worrying result as the community is currently very much score driven, and yet these can just be artifacts of randomness.”
Large Scale datasets
Author uses pretrained models which are fine tuned and evaluated in ImageNet to see if by using larger training set with a pretrained model still shows randomness in scores with respect to seed (50 seeds were used for ImageNet experiment).
As per the accuracies reported, there is standard deviation of 0.1% and the difference between minimum and maximum values is about 0.5%. This difference is less than that seen in CIFAR10 experiments — this is still surprising as all the experiments were ran using same initial pretrained weights apart from last layer. Only image batches varies as per the seed set. A difference of 0.5% in ImageNet is very significant value which will determine whether to publish the work or not.
The answer to the third question is mixed — using pretrained models reduce the variation induced by the seed we choose. But the variation is still has to be considered as even 0.5% is still considered as significant improvement in vision community.
For large dataset such as ImageNet, it will be good if more than 50 seeds is scanned to study if choice of seed affects the accuracy even for pretrained models on large scale datasets.
Discussion
- “What is the distribution of scores with respect to the choice of seed? ” — “Once the model converged, this distribution is relatively stable which means that some seed are intrinsically better than others.”
- “Are there black swans, i.e., seeds that produce radically different results?” — “Yes. On a scanning of 104 seeds, we obtained a difference between the maximum and minimum accuracy close to 2% which is above the threshold commonly used by the computer vision community of what is considered significant.”
- “Does pretraining on larger datasets mitigate variability induced by the choice of seed?” — “It certainly reduces the variations due to using different seeds, but it does not mitigate it. On Imagenet, we found a difference between the maximum and the minimum accuracy of around 0.5%, which is commonly accepted as significant by the community for this dataset.”
In the end the author suggests the researchers to study the randomness of different seeds on their experiments and asks them to report average, minimum, maximum and standard deviation scores.
