Paper Summary — ShuffleNetv2 : Practical Guidelines for Efficient CNN Architecture Design
In this paper, authors have discussed how using only FLOPs (floating point operations per second) doesn’t determine the actual speed of the CNN architecture. They emphasis on measuring memory access cost and consider the hardware on which it is running on.
The paper is quite old (published on July 30, 2018) but explains how one should go about designing and determining the inference speed of their CNN architecture.
Paper link — https://arxiv.org/pdf/1807.11164.pdf
Note — “Any line I quote from the paper will be inside quotes, bold and italics”
The objective of the paper was to propose a direct metric to evaluate the architecture on target platform and also share few practical guidelines for building efficient architectures.
Introduction
The authors discuss that, besides accuracy, the computational complexity is also an important factor that determines the overall performance of the model. A model could have very high accuracy under decent FLOPs, but while actual inference, it would be accessing the memory very frequently leading to slow inference.
Recently, we have seen efficient architectures being built for less computational power devices leading to lesser FLOPs. Such architectures include Group convolution and Depth-wise convolutions. So, while benchmarking the speed, authors use FLOPs to show the difference between their speed.
But, for example, MobileNetv2 is faster than NASNET-A, but their FLOPs are similar! This shows that using only FLOPs, we would never know the actual speed.
Authors propose 2 more metrics apart from FLOPs — Memory Access cost (MAC) and Degree of Parallelism.
MAC constitutes a large portion of entire model runtime in operations such as Group Convolution. Model with high degree of parallelism (ability to perform calculations parallelly), will run much faster!
Authors propose two principles that should be taken into account for designing efficient networks
- Direct metric such as speed instead of FLOPs which is indirect metric
- Evaluating the metric on target platforms
Practical Guidelines for Efficient Network Design
- Equal channel width minimizes memory access cost (MAC) : This means, by keeping same number of channels across the architecture, reduces the memory access cost and time as memory access patterns become more predictable and the CPU can keep the data ready before itself.
- Excessive group convolution increases MAC : In group convolution, the intermediate input channels are divided into groups and then the filters are multiplied with them and then outputs from all the groups are concatenated. This reduces the computation cost and the operations become much faster. But, if we increase the number groups to a bigger number, more data moves to and fro while computation leading to more time.
- Network fragmentation reduces degree of parallelism : The degree of parallelism refers to the ability to perform multiple computations simultaneously. In a parallel computing environment, such as a multi-core CPU or a GPU, parallelism is key to achieving high performance.
Network fragmentation means breaking down the neural network into smaller components to optimize memory usage or perform computation parallelly like in Group convolution.
So, what it means is, if we fragment the model into various parts, these smaller parts won’t be able to fully utilize the parallel processing ability leading to increase in time. It may happen because some parts would be computed very fast and other might take time, leading to more time to concatenate the results for next layer!
“Though such fragmented structure has been shown beneficial for accuracy, it could decrease efficiency because it is unfriendly for devices with strong parallel computing powers like GPU. It also introduces extra overheads such as kernel launching and synchronization” - Element-wise operations are non-negligible : Element-wise operations such as ReLU are simple and require less computational cost. But in Deep neural networks where we have millions of parameters, this simple calculation contributes to increase in overall time taken by the network.
Based on above guidelines, authors had concluded that an efficient architecture should
- use ”balanced“ convolutions (equal channel width)
- be aware of the cost of using group convolution
- reduce the degree of fragmentation
- reduce element-wise operations.
These desirable properties depend on platform characteristics (such as memory manipulation and code optimisation) that are beyond theoretical FLOPs. They should be taken into account for practical network design
ShuffleNetV2
Review of ShuffleNetV1
ShuffleNetV1 was introduced for running on resource-constrained devices. It was quite efficient and accurate. Since it was designed for running on less resources, we couldn’t just increase the number of feature maps to improve its performance. One way could be to add pointwise group convolution and bottleneck structures. Also, a channel-shuffle operation was introduced to promote cross-channel communication and improve the representational power of convolutional neural networks (CNNs) while maintaining low computational complexity.
As discussed before, point-wise group convolution and bottleneck structures increases MAC violating Guideline 1 & Guideline 2 of the guidelines. If we follow the above guidelines, by adding more groups, we violate Guideline 3. If we use element-wise “Add” operation, it violates Guideline 4. The only way to improve accuracy, while following all the above guideline, was to tackle the problem of maintaining high number of and equally wide channels, with neither dense convolutions nor too many groups.

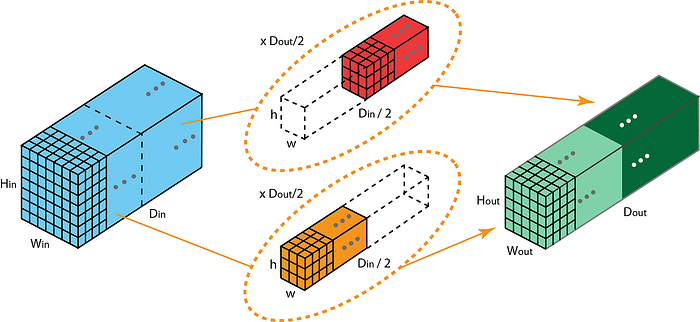
Group Convolution
The current set of feature maps which are input to the Group convolution, are divided into groups and then the filters are applied on separate groups. Post this, the results are concatenated.
Channel Shuffle
Post Group-shuffle, channels from different groups are interchanged or shuffled to create a new order of channels. The specific shuffling pattern can vary but typically involves reordering the channels in a way that allows cross-channel interactions.
Benefits:
- Information Flow: Channel shuffle facilitates the exchange of information between channels that were originally in different groups. This cross-channel communication can help capture more complex and abstract features in the data.
- Improved Representations: By allowing channels to interact, the network can learn richer representations of the input data, potentially leading to better feature extraction and classification.
- Efficiency: Despite enabling greater expressiveness, channel shuffle doesn’t significantly increase the computational cost. It leverages the grouped convolution’s efficiency to manage channel interactions without a substantial computational overhead.
ShuffleNetV2
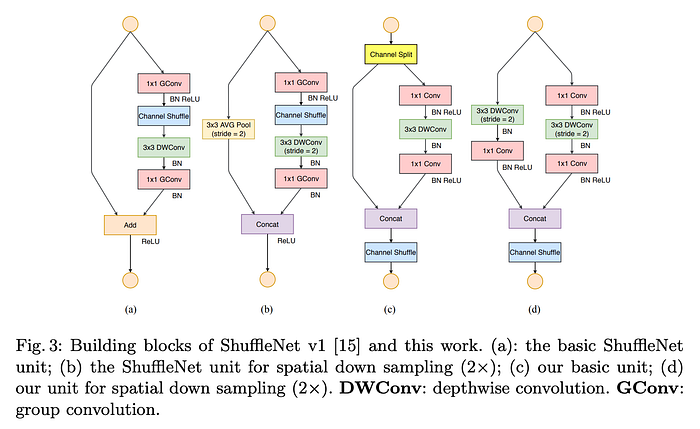
In ShuffleNetV2, Channel Split was introduced. In this, the channels, are split into two branches. One branch remains as identity, following Guideline 3. The other branch has three conv operations having same input and output channels, following Guideline 1. The two 1x1 convs are no longer group-wise as split operation already produces two groups, following Guideline 2. “Concat, Channel shuffle and Channel split are merged into a single element-wise operation.” This follow Guideline 4.
This was a short summary of this paper. I didn’t cover experiments as you will get better & in-depth idea if you go through this section on the paper itself. The paper is quite easy to understand and the experiments section is worth exploring.
My idea was to introduce readers to this paper and cover the core concepts of it.
Thanks for reading :). Please follow for monthly dose of Paper Summary and also do connect with me on LinkedIn.
