Paper Summary — MetaFormer is Actually What You Need for Vision
In recent times we have seen that Transformers (for vision) have performed very well, i.e., at par or at times surpassing the previously claimed SOTA for vision. The heart of the Transformer is the attention based token mixer which was applauded for the results the transformers gave in other fields as well.
Now, what if I tell you, you replace that entire Attention based token mixer (which takes in key, value and query and does wonders), and replace that with just a Pooling layer and the result you will get will be at par with many SOTA architectures!
Can you believe? Just simple Pooling operations, (MaxPool, AvgPool, etc in vision) which has no parameters, perform at par with Attention Mechanism!? Even I did not believe until I read the paper — MetaFormer is Actually What You Need for Vision (link).
Note — If I quote anything from the paper it’ll be italic and inside quotes. For example — “this is an example”
Abstract
It was believed that the attention module of the transformer contributed most to it’s amazing performance but later when it was replaced by spatial MLPs, it still gave good results. So, as per the authors, it means that, apart from the attention module, the general architecture of the transformer contributes to its performance.
To verify this, the authors replaced the attention module with a non-parametric pooling layer (they called the model as PoolFormer) and the results were still good! This result encourages the authors to move ahead and propose the concept of “MetaFormer” where the general architecture of the transformer is used without any specific token mixer.
Introduction
The attention module for mixing information among tokens in the transformer’s encoder is termed as “token mixer”. Believing the attention mechanism to be the reason behind transformer’s performance, many works have been proposed surrounding this concept.
But some of the recent works, replaced the attention module with a Fourier Transform and still performed very well, attaining 97% of the accuracy of Vanilla transformer. So this shows that, if we use MetaFormer (the general architecture of the transformer having any computation in the place of attention module) as the general architecture, good results are attained.
PoolFormer, proposed by the authors, outperforms fine-tuned transformers and MLP like models.
Contributions of the paper are :-
- “Abstract transformers into a general architecture MetaFormer”
- Authors evaluate PoolFormer in multiple tasks such as Classification, object detection, semantic segmentation and instance segmentation and it “achieves competitive performance compared with the SOTA models using sophistic design of token mixers.”
Method
MetaFormer
“Input I is first processed by input embedding such as patch embedding in VITs.”
X = InputEmb(I)
Where X is a matrix of real number of dimension NxC, N is for squence length and C is embedding dimension. “Then embedding tokens are fed to repeated MetaFormer blocks, each of which includes two residual sub-blocks. The first sub-block mainly contains a token mixer to communicate information among tokens” and its represented as
Y = TokenMixer(Norm(X)) + X , where Norm is Layer Normalization or Batch Normalization and TokenMixer is a module for mixing information like attention, Spatial MLP, etc
“The second sub-block consists of two-layered MLP with non-linear activation”
Z = NonLinearActivationFunction(Normalization(Y) * W1) * W2 + Y
where W1 is matrix of real numbers of dimension C x rC and W2 is matrix of real numbers of dimension rC x C. W1 & W2 both are learnable parameters with MLP expansion ratio r.

PoolFormer
The authors use Pooling Operation as Token Mixer in the general architecture proposed above that is MetaFormer. This operation has no parameters which can be learnt and “it just makes each token averagely aggregate its nearby token features”. Spatial MLP and Self attention have quadratic computational complexity where as pooling has linear computational complexity.
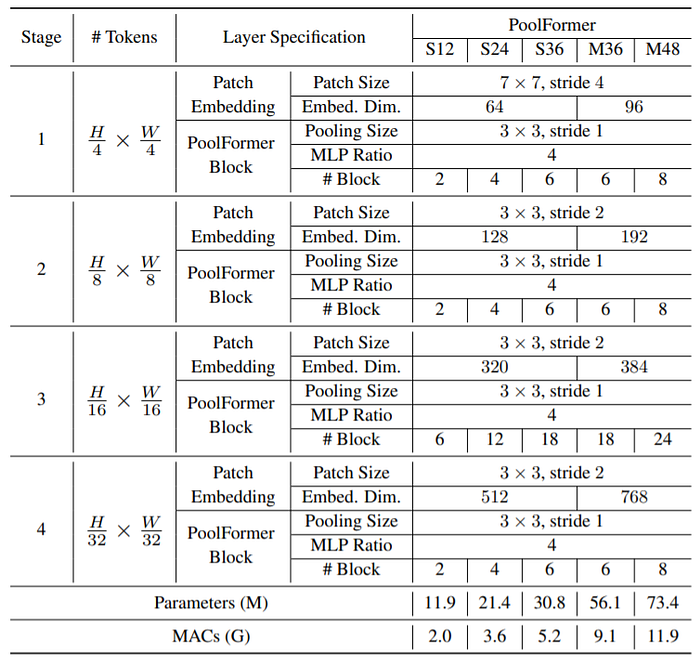
“PoolFormer has 4 stages H/4 * W/4, H/8 * W/8, H/16 * W/16 and H/32 * W/32. There are two groups having different embedding size :-
- small-sized models with embedding dimensions of 64, 128, 320, and 512 responding to the four stages;
- 2) medium-sized models with embedding dimensions 96, 192, 384, and 768.
Assuming there are L PoolFormer blocks in total, stages 1, 2, 3, and 4 will contain L/6, L/6, L/2, and L/6 PoolFormer blocks respectively. The MLP expansion ratio is set as 4. According to the above simple model scaling rule, we obtain 5 different model sizes of PoolFormer and their hyperparameters are shown” below.
Results
For ImageNet, PoolFormer-S24 has top-1 accuracy greater than 80% with only 21M parameters and 2.6G MACs whereas DeiT-s achieves 79.8 but requires 4.6G MACs. ResMLP-S24 needs 30M parameters andd 6G MACs with accuracy of 79.4.
Conclusion
Recently we have seen how simple architectures or simple practices (such as MLP Mixer, ResNet Strikes back and Patches are all you need) are overcoming complex SOTA architectures. Even in this paper we saw how simple Pooling operation performs better/at-par with Attention based module in Transformer for Vision.
“This finding conveys that the general architecture MetaFormer is actually what we need when designing vision models. By adopting MetaFormer, it is guaranteed that the derived models would have the potential to achieve reasonable performance.”
For experiments, detailed results and other details, I highly recommend you to read the paper as you will get in-depth insights about all these topics.
This summary was short as the idea being conveyed was simple and precise in the paper.
Thanks for reading :). Do follow me on Medium to get paper summaries every month.
Connect with me on LinkedIn too :D.
