Paper Summary — Deep Leakage from Gradients
Paper Link — https://arxiv.org/abs/1906.08935
Why this topic?
While performing distributed training to speed up training, the gradients gets shared across GPUs and while working with Federated learning, the gradients are shared over a central server. The users used to believe that these gradients are safe to share and it’s leakage cannot lead to the actual data. In this paper, the authors talk about how gradients from these techniques can leak and how these leaked gradients can be used to generate actual input data and label. The authors also discuss ways to prevent the leakage of gradients. It also tells us how to prevent Gradient leakage when using newer techniques to train models in different environments.
In this paper, the authors show that their attack is able to recover pixel by pixel images and token-wise texts from the gradients.
The safest way to prevent leakage without changes to the training settings is Gradient Pruning.

Introduction
When training models using the concept of distributed training, it naturally splits the data across workers. Each client has its own training data and only gradients are shared. This scheme is used for training models on private data and its known as Collaborative learning. This allows us to train models without centralizing the data coming from multiple sources.
Recent studies have shown that the gradients being shared in such training methods can reveal some properties of the training data. Using generative adversarial networks with gradients, its possible to generate data similar to the training data.
In this paper, authors demonstrate “Deep Leakage Gradient”, sharing the gradients can leak the training data. In this methods, authors show that how in few iterations, it was possible to generate the input data and the labels.
How did the authors do it? — Quoting from the paper :
“We first randomly generate a pair of dummy inputs and labels then perform the usual forward and backward. After deriving the dummy gradients from the dummy data, instead of optimizing model weights as in typical training, we optimize the dummy inputs and labels to minimize the distance between dummy gradients and real gradients. Matching the gradients makes the dummy data close to the original ones. When optimization finishes, the private training data will be fully revealed.”
DLG doesn’t require any extra training points. It can infer from the label from shared gradients and the DLG can produce the exact original training samples instead of similar looking data.
How to prevent Gradient leakage?
- Gradient perturbation — By adding Gaussian or Laplacian noise of scale higher than 10^-2 acts as a good defense
- Low precision — By using lower precision, it still failed to protect the gradients
- Gradient compression — Successfully defends the attack with the pruned gradient is more than 20%
Contribution by the paper
- Its possible to obtain the private training data from publicly shared gradients.
- DLG requires only the gradients and can reveal pixel-wise accurate images and token-wise matching texts.
- Discuss few defense strategies against the attack
Distributed Training
Its computationally expensive to train large machine learning models, hence we opt for distributed training methods. Most of the methods adapt synchronous SGD as the backbone because the stable performance while scaling up.
Distributed training is of two types — Centralized and Decentralized.
For centralized (with parameter server), each node first performs the computation to update its local weights and then send the gradients to other nodes. All training data and computation are concentrated in a single central location or server. The central server is responsible for processing the entire dataset, computing gradients, and updating the model parameters.
For decentralized (without parameter server), gradients are exchanged. In decentralized machine learning training, the training process is distributed across multiple computing nodes or devices. Each node processes a subset of the training data and computes gradients locally.
Recently, collaborative training has emerged where two or more participants can jointly train a model where the data never leaves participant’s local server. Only the gradients are shared.
Method
Training data leakage through Gradient Matching
(Please refer to Method section of the paper to get detailed understanding)
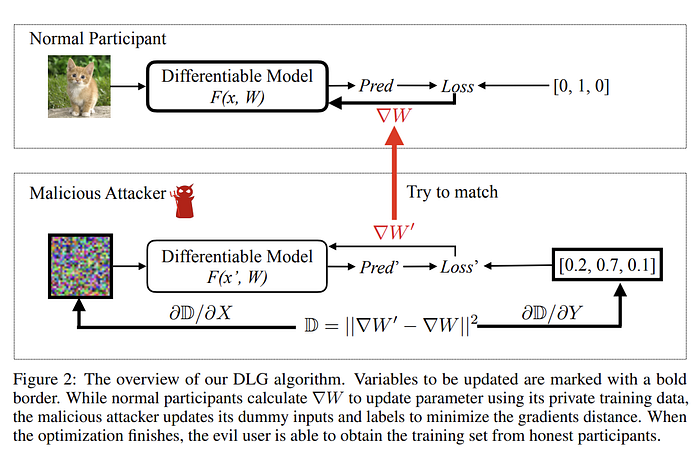
- Initialize dummy input x’ and label y’.
- Feed these dummy data into models and get dummy gradient
- Parallel train the original model, where gradients are being shared.
- Fetch the dummy gradients and actual gradients and match them by calculating the distance.
- The dummy gradient is then modified depending on the error/difference in distance and then the dummy model weights’ are updated.
The main requirement is that the gradients should be differentiable twice. The optimization requires 2nd order derivatives.
Deep Leakage for Batched Data
The DLG algorithm works well only for single pair of input and label in the batch. When the number of data in a batch increases, the algorithm becomes slow as the batched data might have N! different permutations and thus makes it hard for the optimizer to choose gradients directions.
With higher batch size, the algorithm is still able to produce the data but the number of iterations required increases significantly.

Experiments
Deep Leakage on Image classification
ResNet-56 was used without strides and ReLU was replaced by Sigmoid so that the model becomes differentiable twice.
The authors start with random Gaussian noise and try to match the gradients produced by the dummy data and real ones. By minimizing the distance between gradients also reduces the gap between the data. It was observed that monochrome images with a clean background (MNIST) were easiest to recover, whie complex images like face took more iterations.
Deep Leakage on Masked Language model
In each sequence, 15% of the words were replaced with a [MASK] token and MLM model attempts to predict the original value of the masked words from a given context. BERT was used as the backbone.
Defense Strategies
Noisy Gradients
Straight forward method is to add noise to the gradients. The authors added Gaussian and Laplacian noise distributions with variance in the range from 10^-1 to 10^-4. They observed that the defence effect mainly depends on the magnitude of distribution variance and less related to the noise types. When the noise was in scale of 10^-4, it didn’t prevent the leakage. Even with 10^-3, the the gradients still leaked. Only with 10^-2, the DLG failed to execute and prevent the data leakage. Laplacian noise performed better and prevented leakage at scale of 10^-3. But by adding noise with variance larger than 10^-2, the accuracy of the actual model will degrade.
By changing the precision of gradents to half, the gradients still leaked. Int-8 was able to reduce the leakage but the accuracy of the real model dropped.
Gradient Compression and Sparsification
Gradients with small values were pruned to zero. It was difficult for the DLG to match the gradients. When the prune ratio was set to 20%, the DLG algorithm was unable to recover the input images. When pruning ratio was increased, the recovered images were no longer recognizable and thus gradient compression successfully prevented the leakage.
In previous experiments it was seen that the gradients were compressed upto 300 times without losing accuracy. In this case, the sparsity was 99% which exceeds the maximum tolerance of DLG(which has tolerance of 20%).
Large Batch, High resolution and Cryptology
Increasing the batch size, increases the difficultly for the DLG algorithm to get the data. Upscaling the images is also a good idea. DLG currently worked for batch size upto 8 and image resolution up to 64x64.
Cryptology can also be used to prevent the leakage of gradient. Its the most sercured way of protecting data/gradients from being leaked. But again, this method has its own challenges and limitations.
Thanks for reading my blog. Follow for more such interesting blogs :)
Do connect with me on LinkedIn.
