Intel OpenVINO in brief
This blog focuses on theoretical and practical knowledge of OpenVINO. It discusses few prominent features of OpenVINO to help you get started.
My system’s config — i5 9th Gen 9300H, 16GB RAM

Contents
- Intro to OpenVINO
- Model Optimizer
- Inference Engine
- Performance Benchmarking
- DL Benchmark
- Conclusion
- Refereneces
Intro to OpenVino
OpenVINO, stands for Open Visual inferencing and Neural Network Optimization, is a tookit to deploy vision based solutions on Intel hardwares. OpenVINO is only used for inference and not training of vision based models. You can deploy your model on the cloud or on the edge having intel hardware.
OpenVINO helps deploy model on Intel CPUs such as Core i5, i7, Xeon or Integrated GPUs such as Intel HD Graphics, Intel Iris or on VPU (Visual Processing Unit) such as Movidius or on Intel FPGAs.
Link to install OpenVINO— Intel’s Site

Model Optimizer
Model Optimizer abstracts the hardware for the user. Different CPUs have different instruction set and architecture. We also have different frameworks available. To help run models from different frameworks on different Intel devices, Model optimizer first converts the model to intermediate representation called IR and then use IR files (weights and architecture files) to inference on different devices be it CPU or GPU. Model optimizer is also hardware agnostic, meaning the IR files generated can run on any target Intel device.
Model Optimizer converts a model from different framework to single representation. Then it optimizes the model using technique such as layer fusion. Then it changes the format in which weights are stored such from FP32 to FP16 or INT8.
IR or Intermediate representation has 2 files — XML file and BIN file. XML file stores the model architecture and BIN file stores the model’s weights.
Model Optimizer supports Tensorflow, Caffe, Kaldi, MXNet and Onnx (as of publishing this blog) as model framework. NO, it doesn’t supports PyTorch natively but you can convert PyTorch model to Onnx and then pass it to the Model Optimizer.
For example, if you want to convert your onnx model to IR
python3 mo_onnx.py --input_model resnet.onnxCheckout this link for other arguements which you can pass.
You can also quantize your model to FP16 and INT8 depending whether or not your target device supports it. Check out the below table.

Model Optimizer lets you resize the input you pass to the first layer of your model. That is, if your model takes image of size 3x224x224, while exporting you can pass the following parameter. This mean you don’t need to retrain your model. By this, all the other layers’ input dimension changes. (Not sure if it works if I want to increase the size of Image and not decrease)
--input_shape [1, 3, 100, 100] Check out the docs to see how you can cut the network or add scale/mean operations to the network.
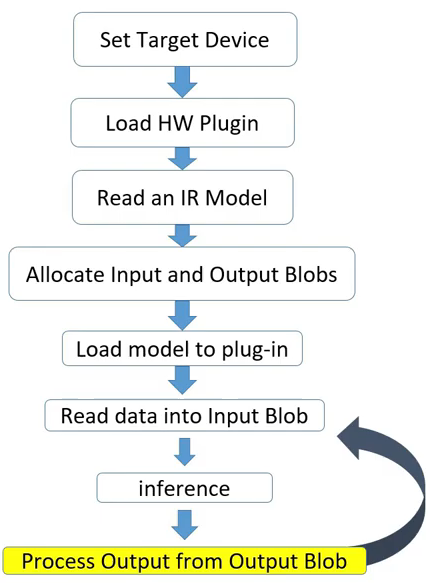
Inference Engine
After having optimised our model, here comes the Inference Engine. Inference Engine(IE) is an API and is common for all Intel hardwares. Implementation of a function (say multiplication) will be different for different devices but the IE has plugins for each device. The user only needs to specify the target device and IE takes care of other things.
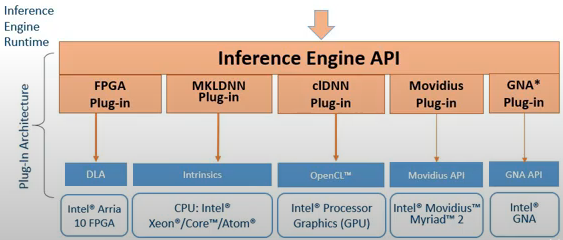
Heterogeneous Plug-in
Above, you saw that you can run same IR on multiple devices. Now, what if I tell you that OpenVINO lets you run different layers on different hardware devices! Yes, OpenVINO supports this and is called — Heterogeneous Plug-in.
Why do we need this? — There might be some layers which is not supported by FPGA but is supported by CPU! If a full network cannot work on one device then we run different layers on different device!
Won’t it be slow? — Yeah it might be slow depending on data transfer speed from one device to another. Not all models would be compatible or at times it won’t be suitable to use this because of throughput.
OpenVINO takes care of precision when switching devices during inference.
Performance Benchmarking
Assume you have a model to deploy but the hardware is not fixed yet. Now you bring in Intel devices which are candidate deployment devices. Now, by using Performance Benchmarking, you can get the throughput of the model, latency and best data format on each of these devices, hence helping you choose the correct one as per your requirements.
You can run benchmarking on synchronous and asynchronous mode, enabling sequential and parallel processing.
Follow this video to see how to use Performance Benchmarking.
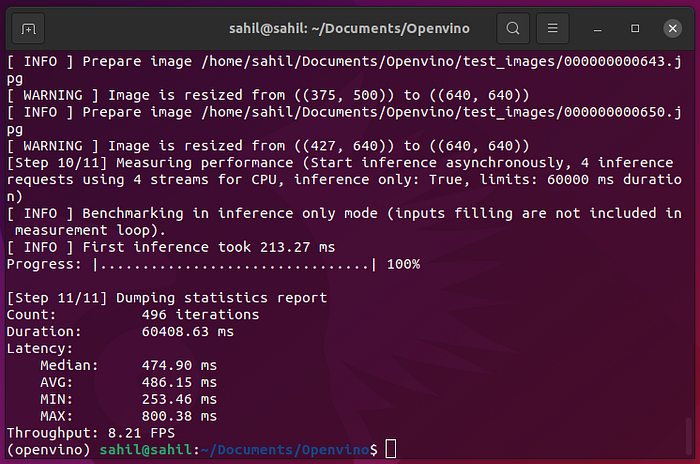
I ran Performance Benchmarking on YoloV5s model by passing 128 images with batch size 1. Here is the output!
DL Benchmark
DL Benchmark provides UI to optimize your model and run several benchmarks. You can set the maximum accuracy drop you would want when optimizing your model! It offers same options just like the command line way but it becomes easy to use.
Watch this to learn more. I would have attached screenshots here but watching this video makes more sense and gives better explanation.
Conclusion
Intel OpenVINO has shown that DL models can be run on CPUs efficiently. This will surely bring down deployment cost as CPUs are relatively cheaper than GPUs. There might some trade offs but I am sure we can find our way out.
So, this blog was just to help you get started with Intel OpenVINO. Do checkout the references for videos from where you can learn more about OpenVINO. Also, do some hands on too! It’s easy to install and use.
Connect with me on LinkedIn and Twitter. :)
Thanks for reading :)
References
[1] OpenVINO Toolkit Tutorial — YouTube Link
[2] Intel Movidius — Intel’s site
[3] Intel FPGAs — Intel’s site
